Usability: Rearranging the Node Form
Mon, 06/15/2009 - 11:48 — cwgordon7I've been working on implementing Leisa Reichelt's . started the process off by creating a to move the submit buttons up to the right, and separate the node form into a "Content" and a "Meta" tab. I refined his patch to make the horizontal tabs a reusable form element, and in the current state of the patch, the node form looks as pictured:
- 10 comments
- Read more
- 750587 reads
How to: Write Automated Tests for Drupal
Mon, 07/14/2008 - 02:02 — cwgordon7With , Drupal is now far along the road to a practice of . But there's one thing missing: a complete, in-depth, up-to-date tutorial on how to actually write these tests. Although there is the module to help you create these tests through the user interface, it is currently imperfect and under development, so this post will be a tutorial on writing these tests manually.
Testing resources
Here's just a general list of resources we should keep handy while writing our test:
- - This is a quick cheat sheet of some functions that are very helpful during testing. These include controlling the internal testing browser, creating users with specific permissions, and simulating clicking on links that appear in the page.
- - Assertions are how you determine whether your code is working or not - you assert that it should be working, and let the testing framework handle the rest for you. This is a library on the assertions that are available to use in our testing framework.
- 7 comments
- Read more
- 610469 reads
Awesomeness and Drupal
Wed, 06/11/2008 - 17:50 — cwgordon7It has recently come to my attention that I was the only one on drupal.org that had as an interest. My complaints on irc sparked the discussion: what does the word "awesomeness" mean? Is it even a word? And why is Drupal pure awesomeness?
So I compiled a list of definitions of "Awesomeness" from the internet:
- 3 comments
- Read more
- 109768 reads
Paris SimpleTest Sprint, Day 2
Sun, 04/20/2008 - 19:02 — cwgordon7
Only hours ago, after over three years of work on the SimpleTest module, . This is an amazing achievement. Drupal is looking at getting 100% core test coverage, both unit and functional. A lot of work went into the SimpleTest module today before it was committed. We (the Drupal SimpleTest Sprinters) set up an SVN repository containing a version of Drupal with SimpleTest there as a module, and opened it up for all of us to commit. It was chaos (in a good way). Without the roadblock of patches, code was rapidly sucked into the SimpleTest module; finally Dries had to give us a SimpleTest "code freeze" so as to actually start to get stuff to work.
Current SimpleTest Status
SimpleTest is in core! What can be left to do? Actually, a lot, but first, let's go over what we've done today:
-
 Got SimpleTest into Core!
Got SimpleTest into Core!
-
Got all tests except for Trigger and Poll tests actually passing!
-
Got PHPCoverage to generate a 500 MB XML file on Rok's laptop! (Though we have yet to find a script that can deal with all that data without crashing).
-
Made SimpleTest's web interface pretty with the addition of icons and assertion groups!
-
Got the code necessary for working!
And then, there are :
- 2 comments
- Read more
- 37521 reads
Paris SimpleTest Sprint, Day 1
Sat, 04/19/2008 - 19:18 — cwgordon7Today we began the code sprint! This is an area of , as one of our weaknesses has proven to be the number of testers we have, particularly how small that number is. Automated testing will provide an easy way to maintain the quality of core— each time a patch is created for core, it will be sent off to a where the patch will be applied to a copy of the Drupal core and all the SimpleTests run on it. If there are failures, the patch would be marked as such and whoever submitted the patch would be forced to hang their head in shame.
What we accomplished today
Today, Dries Buytaert, Rok Žlender, Károly Négyesi, Jimmy Berry, Kevin Bridges, Douglas Hubler, Miglius Alaburda and I got together for 10 hours for the sole purpose of improving automated testing in core. It was great. We bounced ideas off one another, and came up with a great plan for unit testing with mock functions and classes without runkit. We made our test coverage tests work, although they are still running :). We gave a presentation to the people at Drupal Camp Paris on how to write basic functional tests for both core and contributed modules. We talked to Dries about the possibility of .
- 3 comments
- Read more
- 54803 reads
Google sponsors two Drupal developers to Testing Sprint, Paris
Wed, 04/09/2008 - 21:08 — cwgordon7
Thanks to the amazing and the awesome , we can add an additional two sprinters to the list for ! Both (me) and (aka boombatower) are now going to be at the testing sprint! Let's all thank for this awesome act of kindness towards the Drupal community!
SimpleTest is critical to Drupal, not only for quality assurance, but also to so we can add more features to Drupal 7 and make it as awesome as possible.
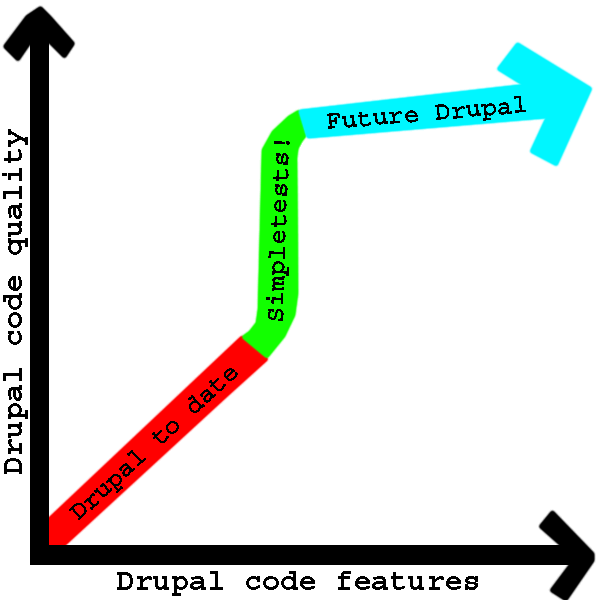
As this beautiful graph clearly shows, after Drupal has made the switch to complete SimpleTest coverage for core, the quality of Drupal will skyrocket, as we will be able to ensure that each patch committed to core does not break any of the SimpleTests, therefore less bugs and more features! When we have complete core SimpleTest coverage for Drupal, we will be free to explore awesome new features instead of spending precious time on bug hunting and bug fixing.
Let's make that Drupal 7 release a killer! :)
- 6 comments
- Read more
- 51522 reads
DROP (Drupal Rockin' Open Participation)
Sat, 02/16/2008 - 03:10 — cwgordon7For those of you who haven't read the front page post yet, is a new program that encourages and helps people get involved in the Drupal community! DROP is basically a continuation of , only extended so that everyone, not just 13-18 year old high school students, can participate.
Have you ever wanted to contribute to Drupal, but weren't sure where to begin? Developers, have you ever seen small tasks on drupal.org that you don't have time for but that are important nonetheless, and would be good for people just starting to learn Drupal? Then DROP is for you. DROP is an organization of small tasks from drupal.org, both documentation tasks and coding tasks—and everyone can participate in it, either by proposing DROP tasks, mentoring them, or doing them. No matter what your skill level and experience with Drupal is, you can find some way to benefit from this new program. Read on to learn more about this program, or to go to the DROP site's about page.
- 9 comments
- Read more
- 65873 reads
GHOP Students at Drupalcon
Tue, 01/22/2008 - 15:58 — cwgordon7Over the past few months, the GHOP program has made innumerable contributions to the Drupal community. Now that GHOP is ending, many of these students are choosing to remain long-term contributors. This is awesome: it's exactly what the program was meant to achieve, getting high school students involved in open source communities. And what better way to get involved in Drupal than to go to Drupalcon?
Deeply inspired by , I have posted here the chipins' of two students requesting financial assistance to get to Drupalcon. Please, please, please seriously consider contributing to this cause. We want new contributors in the Drupal community? Well, here they are: but they need your help to fully join the community.
- Add new comment
- Read more
- 72978 reads
Introducing Flexifilter
Sat, 01/12/2008 - 23:55 — cwgordon7Today, the initial version of for Drupal 6.x was released. "What is this flexifilter?" you might ask. And the answer: Flexifilter is an awesome new module that's going to totally revolutionize the way filters are done in Drupal. It's going to become (almost) as important as CCK and Views for a site builder. Flexifilter was initially created by as a part of .
What it is
Flexifilter allows you to define custom filters entirely through the user interface. You name a filter, you can create it. A filter to append a "back to top" link if the text is longer than 1000 characters? No problem. A filter to change links in the form of [[link|title]] into links in the form of <a href="link">title<a>? Downright easy. And, if you ever want to change the format from [[link|title]] to {{link:title}}, there will be no delving into php code necessary: just change your settings on the admin page.
- 11 comments
- Read more
- 86934 reads
How to: create a wiki with Drupal
Thu, 12/27/2007 - 21:33 — cwgordon7Over the past two years, Drupal's wiki capabilities have expanded exponentially. Yet, still we get support requests on the forums, "How can I make a wiki with Drupal?" Well, here is a detailed plan that gives wiki functionality to Drupal. This tutorial assumes you're starting with an installed version of Drupal 5.x, and that you're familiar with installing modules.
Absolute Wiki Essentials:
- Step 1: Allow for categorization of wiki pages.
There is often this request: I want to be able to categorize my wiki pages into a hierarchy. Well, with Drupal core's book module, you can do just that! First, enable the book module. Then, go to the admin/content/types page to view your content types. Delete any content types you don't want. Then, rename the "Book page" content type to "Wiki page" or something similar. Also, in the "workflow" fieldset, make sure to check the "create new revision" checkbox. This will make it so that, by default, every edit of a page is done in a revision.
- 44 comments
- Read more
- 568931 reads
Recent comments
7 years 2 weeks ago
7 years 7 weeks ago
7 years 16 weeks ago
7 years 21 weeks ago
7 years 21 weeks ago
7 years 21 weeks ago
7 years 22 weeks ago
7 years 29 weeks ago
7 years 29 weeks ago
7 years 29 weeks ago